Large-scale endeavors like RT-1[1] and widespread community efforts
such as Open-X-Embodiment have contributed to growing the scale of robot
demonstration data. However, there is still an opportunity to improve the quality,
quantity, and diversity of robot demonstration data. Although vision-language
models have been shown to automatically generate demonstration data, their utility
has been limited to environments with privileged state information, they require
hand-designed skills, and are limited to interactions with few object instances. We
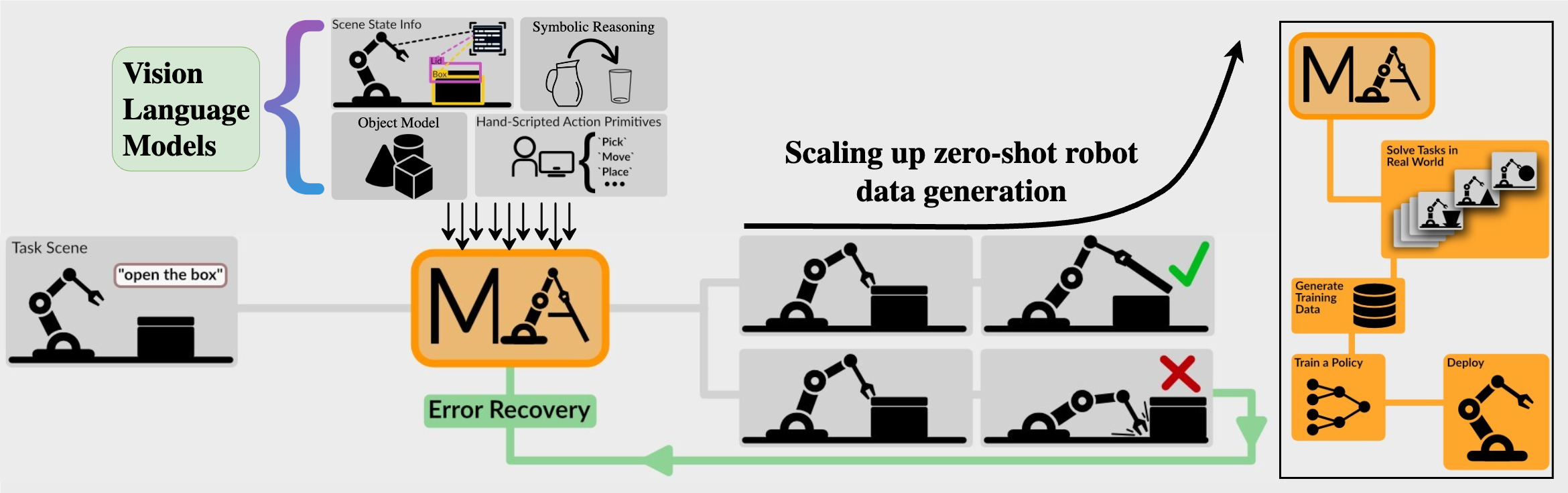
propose MANIPULATE-ANYTHING, a scalable automated generation method for
real-world robotic manipulation. Unlike prior work, our method can operate in
real-world environments without any privileged state information, hand-designed
skills, and can manipulate any static object. We evaluate our method using two
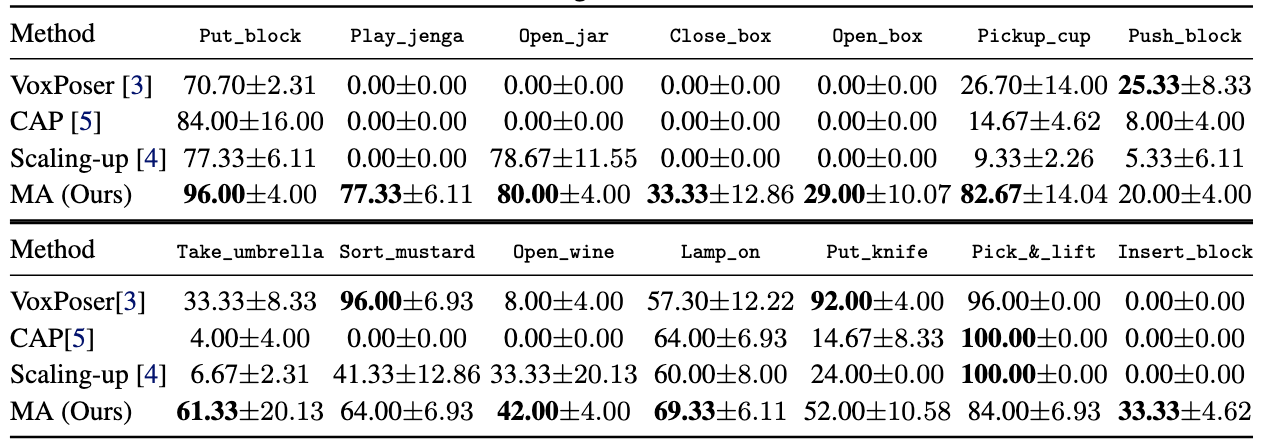
setups. First, MANIPULATE-ANYTHING successfully generates trajectories for all
7 real-world and 14 simulation tasks, significantly outperforming existing methods
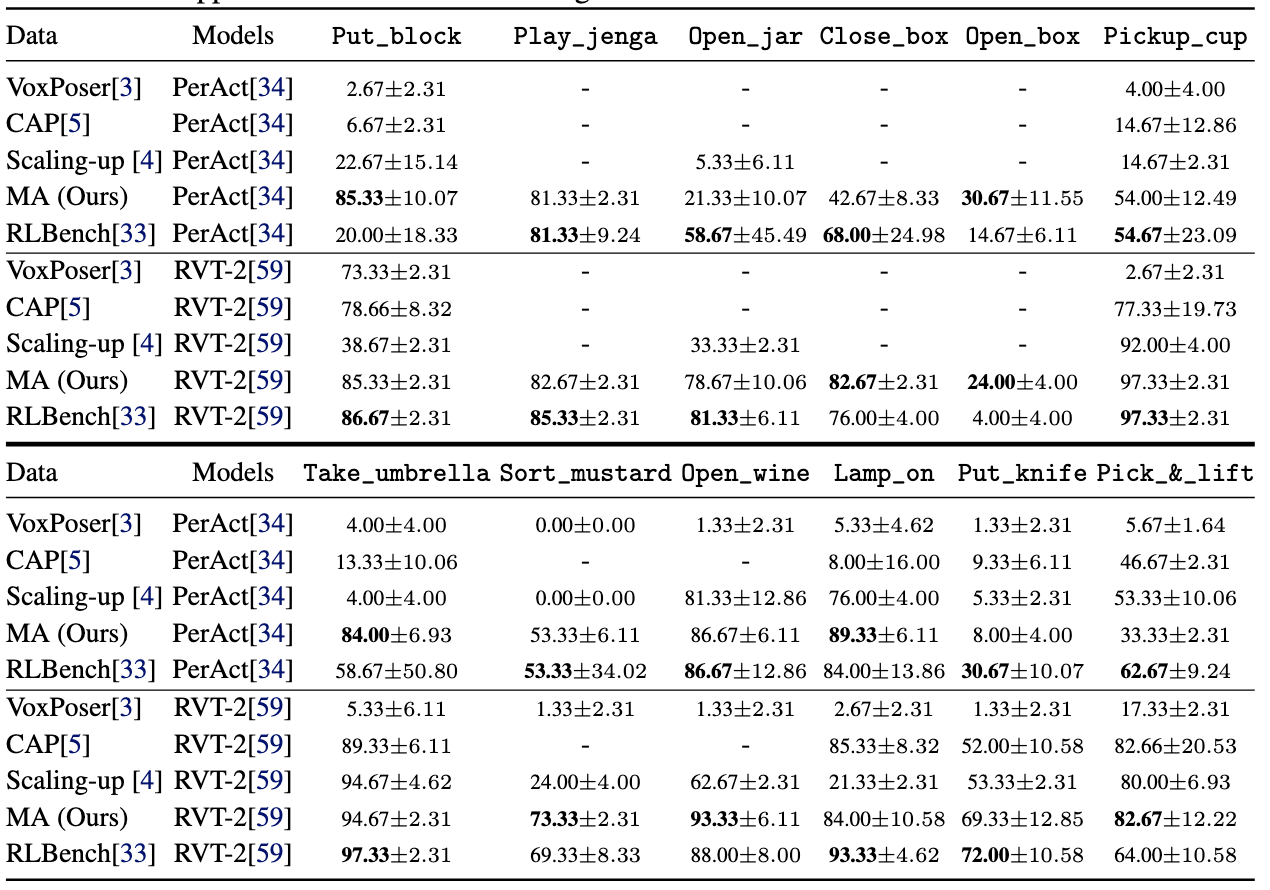
like VoxPoser. Second, MANIPULATE-ANYTHING’s demonstrations can train
more robust behavior cloning policies than training with human demonstrations,
or from data generated by VoxPoser, Scaling-up-Distilling-Down and Code-As-Policies
[5]. We believe MANIPULATE-ANYTHING can be the scalable method for both
generating data for robotics and solving novel tasks in a zero-shot setting